I found a few bugs related to Corpus/Database file handling in the Advanced mode. Also, a serious bug was reported, so I fixed them and uploaded the latest beta to the site. If you have downloaded beta 1.8, please visit the site and download the latest beta. The latest beta is also version 1.8, but if you could run and check About CasualConc, it should say Version 1.8 (20101104).
If you still cannot run this version or find another bug, please report it to me. You can email me or post comment on the blog or send message on Twitter.
Thursday, November 4, 2010
Monday, November 1, 2010
A minor update to CasualConc Beta
I added a few features (some new and some enhanced) to CasualConc Beta. I also enabled an experimental gapped n-gram list feature.
Documentation is not updated, so you might need to figure out how to use some of the features.
General
- Spelling variation feature. You can register spelling variations (i.e. analyze-analyse) and use them in Concord/Cluster/Collocation searches as well as in Word List.
- You can assign different corpus/database file to the left and right tables in Cluster/Word Count in Advanced Corpus Handling Mode.
Concord
- Sorting now has 4th elements.
Cluster
- longer cluster search (up to 8 words)
Word List- Gapped n-gram (3-5 gram)
Concordance Plot
- You can export selected concordance plot as JPEG files (individually) or print them (= export as PDF).
The spelling variation feature is to accommodate word search/word list creation in languages that have spelling variations (i.e. American/British English). Once you create a spelling variation list, you can use information on it when searching a word/creating a word list. There is one problem with this feature. Unless your corpus and spelling variation list are not pos-tagged, CasualConc cannot distinguish the same spelling of different word classes (i.e. analyses [v] vs analyses [n]). A sample list of spelling variations is included in the disk image. You can import it to CasualConc to see how this feature works. You might want to create your own list (there might be some errors in my list and it is far from complete).
For corpus handling, I added a feature to assign different corpus/database file to the left/right tables in Cluster and Word Count. This is available in Advanced Corpus Handling Mode. If you have more than one corpus or database file registered on the table and check more than one corpora or database files, you can select one corpus/database file or All for each of the two tables in Cluster and Word Count. You need to do this in File view.
In Concord, you can select 4th sorting position. I don't know how useful this feature is, but I wanted this from time to time, so I added it. Also related to Concord is Concordance Plot export. Now you can export Concordance Plots. There are two types. One is to export selected plots individually as JPEG files. You can select the ones you want to export on the plots. Another is to print the selected plots. Thanks to OS X's "Save as PDF" feature, you can save the plots as a single PDF file. Now that you can export plots, you might want to change the size of plots, I guess. So I added a feature to change the hight and width of plot boxes. You can set them in Preferences -> Others.
In Cluster, you can create a Cluster list of up to 8 words (= 7 + search word).
In Word List, you can search gapped n-grams (2-5 grams). This feature was already introduced as an experimental feature. I enhanced it a bit and enabled it. I'm thinking about enhancing this feature, but I decided to release it before that hoping to get some feedback (to decide how to enhance this feature).
There might be bugs related to these new features. Any feedback and/or bug report is welcome.
Documentation is not updated, so you might need to figure out how to use some of the features.
General
- Spelling variation feature. You can register spelling variations (i.e. analyze-analyse) and use them in Concord/Cluster/Collocation searches as well as in Word List.
- You can assign different corpus/database file to the left and right tables in Cluster/Word Count in Advanced Corpus Handling Mode.
Concord
- Sorting now has 4th elements.
Cluster
- longer cluster search (up to 8 words)
Word List- Gapped n-gram (3-5 gram)
Concordance Plot
- You can export selected concordance plot as JPEG files (individually) or print them (= export as PDF).
The spelling variation feature is to accommodate word search/word list creation in languages that have spelling variations (i.e. American/British English). Once you create a spelling variation list, you can use information on it when searching a word/creating a word list. There is one problem with this feature. Unless your corpus and spelling variation list are not pos-tagged, CasualConc cannot distinguish the same spelling of different word classes (i.e. analyses [v] vs analyses [n]). A sample list of spelling variations is included in the disk image. You can import it to CasualConc to see how this feature works. You might want to create your own list (there might be some errors in my list and it is far from complete).
For corpus handling, I added a feature to assign different corpus/database file to the left/right tables in Cluster and Word Count. This is available in Advanced Corpus Handling Mode. If you have more than one corpus or database file registered on the table and check more than one corpora or database files, you can select one corpus/database file or All for each of the two tables in Cluster and Word Count. You need to do this in File view.
In Concord, you can select 4th sorting position. I don't know how useful this feature is, but I wanted this from time to time, so I added it. Also related to Concord is Concordance Plot export. Now you can export Concordance Plots. There are two types. One is to export selected plots individually as JPEG files. You can select the ones you want to export on the plots. Another is to print the selected plots. Thanks to OS X's "Save as PDF" feature, you can save the plots as a single PDF file. Now that you can export plots, you might want to change the size of plots, I guess. So I added a feature to change the hight and width of plot boxes. You can set them in Preferences -> Others.
In Cluster, you can create a Cluster list of up to 8 words (= 7 + search word).
In Word List, you can search gapped n-grams (2-5 grams). This feature was already introduced as an experimental feature. I enhanced it a bit and enabled it. I'm thinking about enhancing this feature, but I decided to release it before that hoping to get some feedback (to decide how to enhance this feature).
There might be bugs related to these new features. Any feedback and/or bug report is welcome.
Friday, October 1, 2010
CasualConc bug fix
I found a bug on CasualConc, so I fixed it.
Concord
- The number of files count was incorrect when used with the context word search option ON
Also on CasualConc beta, a little more serious bug was found in the database mode.
General
- Results of Cluster, Collocation, and Word Count were incorrect when the context word search option was ON and a context word(s) was specified in Concord. This happened ONLY in the database mode. There was a bug in creating an SQL query.
If you find any other bugs, please let me know.
Concord
- The number of files count was incorrect when used with the context word search option ON
Also on CasualConc beta, a little more serious bug was found in the database mode.
General
- Results of Cluster, Collocation, and Word Count were incorrect when the context word search option was ON and a context word(s) was specified in Concord. This happened ONLY in the database mode. There was a bug in creating an SQL query.
If you find any other bugs, please let me know.
Tuesday, September 28, 2010
CasualConc beta another minor update
I found a bug in the process to add files to an existing database file, so I fixed it and made some minor changes to corpus file handling in advanced mode.
File (in Advanced Corpus Handling mode)
- you can now add files to an existing database file (this feature was broken)
- you can delete multiple files from a corpus/database file
- you can find duplicate files in a corpus/database file -> identify files with the same path
- you have an option to move a database file to Trash when you delete one from the table
The bug I found was in the process of adding files to an existing database file. This worked long time ago and I somehow broke it when I made changes in the process. But since I haven't got any bug report, I guess no one really uses this function.
And when I fixed this, I also made some changes in corpus handling in the advanced corpus handling mode. Now you can select multiple files on the corpus/database content table (lower left). This means you can delete multiple files at one go. Related to this, I added a feature to identify duplicate files in the selected corpus/database file. If CasualConc find duplicate files, the ones added first (older ones) are selected. Once files are selected, you can delete them at once.
Also you can now move a database file to Trash when you remove it from the database list table.
Finally, I added alert messages related to the corpus handling. When a corpus/database file was not selected or files are not added to a table to process, CasualConc simply ignored button clicking. Now, it gives you a message explaining why CasualConc doesn't process your request in the file view (in most of the cases).
As always, if you find any bug, please let me know.
File (in Advanced Corpus Handling mode)
- you can now add files to an existing database file (this feature was broken)
- you can delete multiple files from a corpus/database file
- you can find duplicate files in a corpus/database file -> identify files with the same path
- you have an option to move a database file to Trash when you delete one from the table
The bug I found was in the process of adding files to an existing database file. This worked long time ago and I somehow broke it when I made changes in the process. But since I haven't got any bug report, I guess no one really uses this function.
And when I fixed this, I also made some changes in corpus handling in the advanced corpus handling mode. Now you can select multiple files on the corpus/database content table (lower left). This means you can delete multiple files at one go. Related to this, I added a feature to identify duplicate files in the selected corpus/database file. If CasualConc find duplicate files, the ones added first (older ones) are selected. Once files are selected, you can delete them at once.
Also you can now move a database file to Trash when you remove it from the database list table.
Finally, I added alert messages related to the corpus handling. When a corpus/database file was not selected or files are not added to a table to process, CasualConc simply ignored button clicking. Now, it gives you a message explaining why CasualConc doesn't process your request in the file view (in most of the cases).
As always, if you find any bug, please let me know.
Wednesday, September 8, 2010
CasualConc beta minor update
I haven't updated this blog for a long time. Since I last posted here, I made a few changes to CasualConc beta.
- Exporting Concord result as RTF
You can now export Concord results as a RTF document. With this format, you can choose to keep coloring of sort words as well as font style of context words.
- Searching Cluster/Collocation from other tools
Though it was not documented on the site, you could run Concord search from the Cluster, Collocation, and Word Count tables. Now you can search Cluster and Collocation from the Word Count table.
If you are using CasualConc beta or want to try the beta, please go to the CasualConc site and download the latest beta.
I'd appreciate any feedback on the beta.
- Exporting Concord result as RTF
You can now export Concord results as a RTF document. With this format, you can choose to keep coloring of sort words as well as font style of context words.
- Searching Cluster/Collocation from other tools
Though it was not documented on the site, you could run Concord search from the Cluster, Collocation, and Word Count tables. Now you can search Cluster and Collocation from the Word Count table.
If you are using CasualConc beta or want to try the beta, please go to the CasualConc site and download the latest beta.
I'd appreciate any feedback on the beta.
Wednesday, June 16, 2010
CasualTextractor documentation and a few minor bug fixes
I finally updated documentation of CasualTextractor. I added quite a lot of features to the PDF mode while ago, but haven't had time to document them. Now the new page is lined from the CasualTextractor page.
Also I fixed a few minor bugs I found while I was documenting it and made a few minor changes to it while I was documenting the new features. The current version is 0.7.1. If you use CasualTextractor or and wanted to know how to use it in the PDF mode, please check the site.
Also I fixed a few minor bugs I found while I was documenting it and made a few minor changes to it while I was documenting the new features. The current version is 0.7.1. If you use CasualTextractor or and wanted to know how to use it in the PDF mode, please check the site.
Friday, April 30, 2010
A CasualConc bug fix
I got a bug report and fixed it (thank you, Adriano).
Bug fix
- crashed when searching with wildcard in the Database mode.
The report was about Concord, but I think it also happened in Cluster and Collocation/Cooccurrences.
This is not a problem on the beta version. I fixed this on the beta when I found this bug, but forgot to apply it to the working version.
You can download CasualConc from the CasualConc site.
If you find any other bugs on the working version (1.0.2), please send a bug report to me. Currently, I'm only using the beta version, so I will only fix bugs which are in common with both the working version and the beta version unless I receive a report.
Bug fix
- crashed when searching with wildcard in the Database mode.
The report was about Concord, but I think it also happened in Cluster and Collocation/Cooccurrences.
This is not a problem on the beta version. I fixed this on the beta when I found this bug, but forgot to apply it to the working version.
You can download CasualConc from the CasualConc site.
If you find any other bugs on the working version (1.0.2), please send a bug report to me. Currently, I'm only using the beta version, so I will only fix bugs which are in common with both the working version and the beta version unless I receive a report.
Wednesday, April 21, 2010
The current status of CasualConc beta
Since it's hard to follow what I've written in the series of posts on the current status of CasualConc beta, I will put the link on this post.
The current status of CasualConc Beta
The current status of CasualConc beta - General/Global
The current status of CasualConc beta - General/Global part 2
The current status of CasualConc beta - Concord
The current status of CasualConc beta - Cluster/Collocation/Cooccurrence
The current status of CasualConc beta - Word Count
The current status of CasualConc beta - Corpus File Information
The current status of CasualConc beta - Interface
The current status of CasualConc beta - experimental features
The current status of CasualConc beta - experimental features 2
I might update these pages or add a new post if I find other features I've added (but couldn't remember when I wrote these).
You can download the beta and the current working version from the CasualConc site (English and Japanese). Please follow the link on the right.
The current status of CasualConc Beta
The current status of CasualConc beta - General/Global
The current status of CasualConc beta - General/Global part 2
The current status of CasualConc beta - Concord
The current status of CasualConc beta - Cluster/Collocation/Cooccurrence
The current status of CasualConc beta - Word Count
The current status of CasualConc beta - Corpus File Information
The current status of CasualConc beta - Interface
The current status of CasualConc beta - experimental features
The current status of CasualConc beta - experimental features 2
I might update these pages or add a new post if I find other features I've added (but couldn't remember when I wrote these).
You can download the beta and the current working version from the CasualConc site (English and Japanese). Please follow the link on the right.
Saturday, April 10, 2010
The current status of CasualConc beta - experimental features 2
This post will be the last of this series of posts 'The current status of CasualConc beta'. The last feature is also a experimental one. It's a gap n-gram list creation (for a lack of better word).
What this does is simple, you can create a n-gram list with one of the words in n-gram (3-5) as a gap or wildcard or whatever you call it. In the experimental beta version, when you select 3-gram, 4-gram, or 5-gram in Word Count, a check box appears.

Check this box and click Count.

Because this process can take a long time and needs a lot of memory if your corpus size is big, a warning message appears. When I tried this with a corpus size of 500,000, this process took almost 10 minutes.
If you are brave enough, this is what you get. The corpus I used is Inaugural Addresses of the Presidents of the United States corpus, prepared by Prof. Tabata at Osaka University for a workshop I attended. As you can see, the gap is represented by * and the words that appear in that slot is in the Gap words column with frequency information.

You can select one of the line and see the entire list of gap words on a table.

Select a line and right click the table.

A panel with a table appears with the list.

You can copy the list and paste it on other applications. In this case all the gap words appeared on the Word Count table, but this is basically designed to see all the words when they are not displayed.

You can see all of them on the table.

OK, that's it. I think I covered almost all the new and enhanced features for the next version (current beta) of CasualConc. The current beta has all these new features except for the last two experimental features. You can download the beta version from Download CasualConc Beta page (Japanese page).
If you are interested in the experimental beta build, please contact me directly at casualconc (at) gmail.com.
Since this is a beta version, CasualConc can be unstable and might have bugs related to the changes I have made. If you ever try this beta version, I'd appreciate your feedback/bug reports.
What this does is simple, you can create a n-gram list with one of the words in n-gram (3-5) as a gap or wildcard or whatever you call it. In the experimental beta version, when you select 3-gram, 4-gram, or 5-gram in Word Count, a check box appears.

Check this box and click Count.

Because this process can take a long time and needs a lot of memory if your corpus size is big, a warning message appears. When I tried this with a corpus size of 500,000, this process took almost 10 minutes.
If you are brave enough, this is what you get. The corpus I used is Inaugural Addresses of the Presidents of the United States corpus, prepared by Prof. Tabata at Osaka University for a workshop I attended. As you can see, the gap is represented by * and the words that appear in that slot is in the Gap words column with frequency information.

You can select one of the line and see the entire list of gap words on a table.
Select a line and right click the table.

A panel with a table appears with the list.

You can copy the list and paste it on other applications. In this case all the gap words appeared on the Word Count table, but this is basically designed to see all the words when they are not displayed.
You can see all of them on the table.

OK, that's it. I think I covered almost all the new and enhanced features for the next version (current beta) of CasualConc. The current beta has all these new features except for the last two experimental features. You can download the beta version from Download CasualConc Beta page (Japanese page).
If you are interested in the experimental beta build, please contact me directly at casualconc (at) gmail.com.
Since this is a beta version, CasualConc can be unstable and might have bugs related to the changes I have made. If you ever try this beta version, I'd appreciate your feedback/bug reports.
The current status of CasualConc beta - experimental features
In this post (and possibly the next) I will present two new experimental features of CasualConc. These two features are still too experimental to be included in a beta on the site. So if you get interested after reading this post, please contact me directly. The email address is on the CasualConc main site.
The first one is visualization of collocations and the second is n-gram search with a gap. I will explain what these mean.
The visualization of collocations is an idea proposed by Prof. Tabata at Osaka University, Japan. This is simply a realization of his idea (not mine). Now, let me show you the current implementation.
To use this function, you need a word list and collocation with the same corpus. So run Word Count and Collocation. The Visual (name is tentative) button is on the Collocation tool. Click it to display the Visualizer panel.

The settings of the Visualizer as follows:

The top one is which statistics to use for visualization. The choices are shown below.

Then select the span/position of collocated words. The upper choice is a position from L5 to R5. If you select R1, only the information on the R1 position (frequency) is used to calculate a selected statistic. If you enable Span, the calculation will be based on the tally of frequency up to the selected position. For example, if you select R3 and check Span, the information in R1, R2, and R3 positions will be used to calculate statistics. The lower choice is a span to the left and right of the keyword. You can select from L1~R1 to L5~R5.

Take xxx words means the first xxx words on the Collocation table will be used for visualization. So if you sort the results on the Collocation table, the words taken from the list will be affected.
Now let's see what this does.

With this setting, the result will look like this. Larger the number, bigger the font size.

This simply reflect the frequency of words in the L1 position. Our (80) is the most frequent and American (40) follows. But the picture is quite different with MI (Mutual information).

You can also incorporate frequency information with other statistic result. If you enable Include Freq Info, the frequency information will be added with a gray scale.

The result will look like this:

If you click Stats button, you can see the actual numbers on a table. You can sort by alphabetical order of words or stats values.

If you check Ignore zero occurrence, words with zero frequency will be removed from the display.


If you choose Log-Likelihood, because of its values, higher values can go extreme, so you can convert LL value with log(10). To enable this, click Convert LL val to log.

With the original LL values, the image will look like this:

With the conversion, it will look like this:

The choice is up to you.
The most experimental part is visualization with 4 statistics. By clicking Use Multiple info, you can incorporate three additional statistics values.
 The current implementation is highly experimental and not tuned to display most effective color scheme, but basic idea is that value of each statistic can be assigned to one of RGB. Higher the value, lower the color value. So if the value for a certain word is high in all three, the font color should be closer to black. If in the above example, Log-Likelihood value is very low and z-score value and Log-log value are very high, the font color should be close to red. These are primary colors, so 100% on all of them means white and 0% on all of them means black.
The current implementation is highly experimental and not tuned to display most effective color scheme, but basic idea is that value of each statistic can be assigned to one of RGB. Higher the value, lower the color value. So if the value for a certain word is high in all three, the font color should be closer to black. If in the above example, Log-Likelihood value is very low and z-score value and Log-log value are very high, the font color should be close to red. These are primary colors, so 100% on all of them means white and 0% on all of them means black.
When the above three statistics are applied with MI as the primary statistic, the image will look something like this:

Blueish or Greenish font colors mean relative values of z-score and Log-log are low compared to a relative value of Log-Likelihood. But the actual values of each statistic can vary a lot, the displayed color scheme may not reflect a true relationships among statistics. I need to figure out the way to visualize the optimum relationships among statistics values. If you have any suggestion, I'd most appreciate it.
Finally, the statistic values of all four indicators can be checked on the stats value table.

You can sort the items by clicking the header of columns.

That's about it. As I mentioned at the beginning, this feature is not available on the current beta. If you'd like to try this, please contact me directly. My email address is on the CauslConc sites (the links are on the right side column of this blog).
The first one is visualization of collocations and the second is n-gram search with a gap. I will explain what these mean.
The visualization of collocations is an idea proposed by Prof. Tabata at Osaka University, Japan. This is simply a realization of his idea (not mine). Now, let me show you the current implementation.
To use this function, you need a word list and collocation with the same corpus. So run Word Count and Collocation. The Visual (name is tentative) button is on the Collocation tool. Click it to display the Visualizer panel.

The settings of the Visualizer as follows:

The top one is which statistics to use for visualization. The choices are shown below.

Then select the span/position of collocated words. The upper choice is a position from L5 to R5. If you select R1, only the information on the R1 position (frequency) is used to calculate a selected statistic. If you enable Span, the calculation will be based on the tally of frequency up to the selected position. For example, if you select R3 and check Span, the information in R1, R2, and R3 positions will be used to calculate statistics. The lower choice is a span to the left and right of the keyword. You can select from L1~R1 to L5~R5.

Take xxx words means the first xxx words on the Collocation table will be used for visualization. So if you sort the results on the Collocation table, the words taken from the list will be affected.
Now let's see what this does.

With this setting, the result will look like this. Larger the number, bigger the font size.

This simply reflect the frequency of words in the L1 position. Our (80) is the most frequent and American (40) follows. But the picture is quite different with MI (Mutual information).

You can also incorporate frequency information with other statistic result. If you enable Include Freq Info, the frequency information will be added with a gray scale.

The result will look like this:

If you click Stats button, you can see the actual numbers on a table. You can sort by alphabetical order of words or stats values.
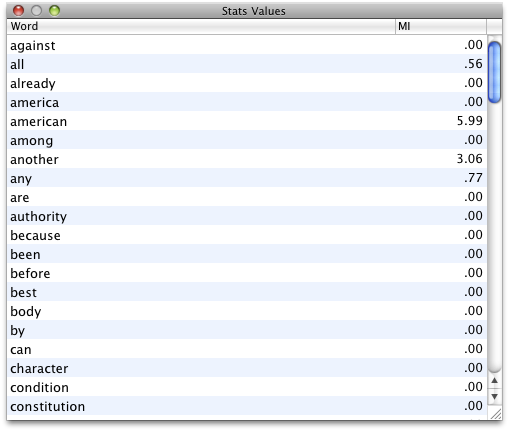
If you check Ignore zero occurrence, words with zero frequency will be removed from the display.


If you choose Log-Likelihood, because of its values, higher values can go extreme, so you can convert LL value with log(10). To enable this, click Convert LL val to log.

With the original LL values, the image will look like this:

With the conversion, it will look like this:

The choice is up to you.
The most experimental part is visualization with 4 statistics. By clicking Use Multiple info, you can incorporate three additional statistics values.

When the above three statistics are applied with MI as the primary statistic, the image will look something like this:

Blueish or Greenish font colors mean relative values of z-score and Log-log are low compared to a relative value of Log-Likelihood. But the actual values of each statistic can vary a lot, the displayed color scheme may not reflect a true relationships among statistics. I need to figure out the way to visualize the optimum relationships among statistics values. If you have any suggestion, I'd most appreciate it.
Finally, the statistic values of all four indicators can be checked on the stats value table.

You can sort the items by clicking the header of columns.

That's about it. As I mentioned at the beginning, this feature is not available on the current beta. If you'd like to try this, please contact me directly. My email address is on the CauslConc sites (the links are on the right side column of this blog).
The current status of CasualConc beta - Interface
The most salient difference in the new version for Japanese users is the interface. If you use CasualConc in Japanese language environment, interface items and messages will be displayed in Japanese. Here is the example from Concord.

Messages are also in Japanese (unless I forgot to change them).


Of course, Preferences are also in Japanese.

When this new version is out of beta, I will include help files in Japanese (the current beta does not have help files included).
OK, this is the end of new feature show case. These should be available in the most up-to-date beta.
For the next couple of posts, I will show you some experimental features. Those are not enabled in the beta on the site, but if you are interested in testing the features, please contact me directly.

Messages are also in Japanese (unless I forgot to change them).


Of course, Preferences are also in Japanese.

When this new version is out of beta, I will include help files in Japanese (the current beta does not have help files included).
OK, this is the end of new feature show case. These should be available in the most up-to-date beta.
For the next couple of posts, I will show you some experimental features. Those are not enabled in the beta on the site, but if you are interested in testing the features, please contact me directly.
The current status of CasualConc beta - Corpus File Information
Perhaps Corpus File Information gets the most enhancement.
In the current working version, Corpus File Info only creates basic file information and the number of n letter words, which is not very interesting. In the new version, you can do a lot more with Corpus File Info.
Corpus File Info now has three modes.

Basic Info is what the current working version does. Basic frequency stats with frequencies of n-letter words. Word Freq Info is to create a frequency matrix (frequencies of specified words in each file). TF-IDF is a measure of prominence or or importance of words in a file. For more information read this Wikipedia entry. To run TF-IDF analysis, you need to run Word Count or import a word list with the information regarding how many files in a provided corpus a certain word appears.
Let me start with Word Freq Info. If you select Word Freq Info, the following items appear on the window.

First you select how you create a list of word you count in the selected corpus.

You can select one of the three sources.
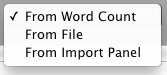
Once you select the source click Import button. You can limit the number of words you import in Preferences -> File Info. If you uncheck this, CasualConc tries to import all the word available in the source.

If you select From Word Count, the words on the left table of Word Count from the first one to the number specified in the Limit or all if not. The order of words to be imported is whatever order on the Word Count. So if you sort the list by alphabets, the imported list is in that order.
If you select From File and click Import, you can import a word list, you will be prompted to specify the format of the word. You can only import a plain text file with a certain format (CSV or tab-delimited). You can specify how many columns from the left or rows from the beginning. You can click Check button to check what will be imported.

If you select From Import Panel and click Import, the import panel appears.

You can directly enter or copy/paste a list (one item/word per line). Once you finish creating a list, click Read button.
You can check what are imported, by clicking Check button on the main window.

You can sort words in alphabetical order by clicking the column header. The last column is the original order of the imported words. You can delete words from the list if you want.
Once you are sure about the list, you can specify the range of words to count. If you want to count only the first 20, you enter 1 and 20 in the boxes.

Then click Get File Info. With the default settings, the result will look like this. The header is the word that were counted and the numbers are the frequencies of the word in each file (and Total).

If you check Normalize word freq in Preferences -> File Info, you can convert the frequency to percent or per xxx words.

If you select %, the result will look like this.

If enable Sort frequency list of each file by word frequency, you can sort the result for each file by the order of frequency index.

If you create a list with percent and sort the result by frequency, you will get a result like this:

The process to import word list is the same for TF-IDF. But to run TF-IDF, you need to have a word list on Word Count and the list should have the information of the number of files a certain word appear in the corpus. If you run Word Count, this information is on the table. Here is the result of the default setting. .00 means the word appears on all the files in the corpus.

You can select how to sort the results in Preferences -> File Info.

If you select Sum of all files, the TF-IDF values for a word will be added up and the sorting is based on the sum of the value of TF-IDF on each file.

If you select Each file, the sorting will be done for each file based on the TF-IDF values.

Personally, I've never used this for my research, but it seems to be a well-known indicator in text mining.
In any case, if you want calculate TF-IDF values for all the words, but only display a limited number of words, uncheck Limit the number of words to import to and import all the words from Word List. Then set Limit result table columns to a reasonable number.

I once tried this with no limits on both with a corpus of about one hundred thousand tokens and the corpus had several thousand unique words. This means the table had several thousand columns. When I tried to scroll the table, even scrolling only one row took several minutes. So don't try it!
In the current working version, Corpus File Info only creates basic file information and the number of n letter words, which is not very interesting. In the new version, you can do a lot more with Corpus File Info.
Corpus File Info now has three modes.

Basic Info is what the current working version does. Basic frequency stats with frequencies of n-letter words. Word Freq Info is to create a frequency matrix (frequencies of specified words in each file). TF-IDF is a measure of prominence or or importance of words in a file. For more information read this Wikipedia entry. To run TF-IDF analysis, you need to run Word Count or import a word list with the information regarding how many files in a provided corpus a certain word appears.
Let me start with Word Freq Info. If you select Word Freq Info, the following items appear on the window.
First you select how you create a list of word you count in the selected corpus.

You can select one of the three sources.

Once you select the source click Import button. You can limit the number of words you import in Preferences -> File Info. If you uncheck this, CasualConc tries to import all the word available in the source.

If you select From Word Count, the words on the left table of Word Count from the first one to the number specified in the Limit or all if not. The order of words to be imported is whatever order on the Word Count. So if you sort the list by alphabets, the imported list is in that order.
If you select From File and click Import, you can import a word list, you will be prompted to specify the format of the word. You can only import a plain text file with a certain format (CSV or tab-delimited). You can specify how many columns from the left or rows from the beginning. You can click Check button to check what will be imported.

If you select From Import Panel and click Import, the import panel appears.

You can directly enter or copy/paste a list (one item/word per line). Once you finish creating a list, click Read button.
You can check what are imported, by clicking Check button on the main window.

You can sort words in alphabetical order by clicking the column header. The last column is the original order of the imported words. You can delete words from the list if you want.
Once you are sure about the list, you can specify the range of words to count. If you want to count only the first 20, you enter 1 and 20 in the boxes.

Then click Get File Info. With the default settings, the result will look like this. The header is the word that were counted and the numbers are the frequencies of the word in each file (and Total).

If you check Normalize word freq in Preferences -> File Info, you can convert the frequency to percent or per xxx words.
If you select %, the result will look like this.

If enable Sort frequency list of each file by word frequency, you can sort the result for each file by the order of frequency index.

If you create a list with percent and sort the result by frequency, you will get a result like this:

The process to import word list is the same for TF-IDF. But to run TF-IDF, you need to have a word list on Word Count and the list should have the information of the number of files a certain word appear in the corpus. If you run Word Count, this information is on the table. Here is the result of the default setting. .00 means the word appears on all the files in the corpus.

You can select how to sort the results in Preferences -> File Info.
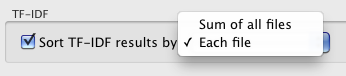
If you select Sum of all files, the TF-IDF values for a word will be added up and the sorting is based on the sum of the value of TF-IDF on each file.

If you select Each file, the sorting will be done for each file based on the TF-IDF values.

Personally, I've never used this for my research, but it seems to be a well-known indicator in text mining.
In any case, if you want calculate TF-IDF values for all the words, but only display a limited number of words, uncheck Limit the number of words to import to and import all the words from Word List. Then set Limit result table columns to a reasonable number.

I once tried this with no limits on both with a corpus of about one hundred thousand tokens and the corpus had several thousand unique words. This means the table had several thousand columns. When I tried to scroll the table, even scrolling only one row took several minutes. So don't try it!
Subscribe to:
Posts (Atom)